


XenServer 6.2 Dynamic Memory and NVIDIA GRID vGPU, Don’t Do It!

Updated 2015.1.13: XenServer 6.5 (aka Creedence) has been released to web and this has been resolved in this release.
Click here to read my updated article for DMC and vGPU on XenServer 6.5
A couple months back I was working with a colleague of mine (Richard Hoffman on LinkedIn or Twitter) on a blue screen issue he identified on a fairly up-to-date XenServer 6.2, XenDesktop, NVIDIA GRID K1/K2 and vGPU deployment. In his case, he was experiencing crashes related to dxgmms1.sys, nvlddmkm.sys, and various other XenServer errors:
xenopsd internal error: Device.Ioemu_failed(“vgpu exited unexpectedly”)
xenopsd internal error: Failure(“Couldn’t lock GPU with device ID 0000:05:00.0”)
Dynamic Memory Control Explained
If you are unfamilar with XenServer Dynamic Memory Control (DMC), you can review this guide:
Like vSphere and Hyper-V memory optimization techniques, DMC allows you to set a minimum and a maximum, low and high watermark, and let the XenServer host manage the allocation to the virtual machine. I have done fairly extensive testing on DMC and its impact to single server density, and there’s definitely some good, bad, and ugly characteristics. The screenshot below is an example of how you would configure Dynamic Memory for a specific virtual machine:
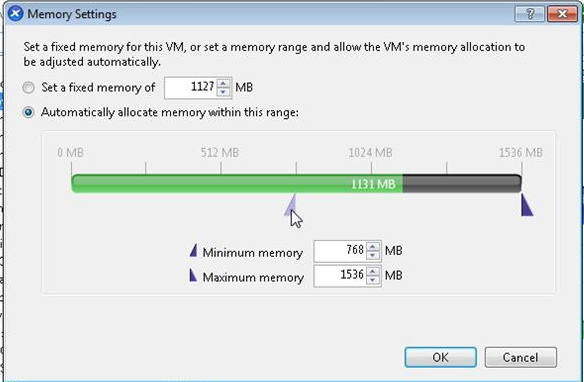
Although it’s been posted for several months in the forums, by my friend and NVIDIA colleague Steve Harpster, in my opinion it not yet common knowledge that for XenServer 6.2 or older, you should NOT configure Dynamic Memory in conjunction with NVIDIA GRID vGPU. This has been resolved for XenServer 6.5! This blog post is my attempt to spread awareness as this can be a very common mistake with unintended consequences. Here’s the explanation from Steve:
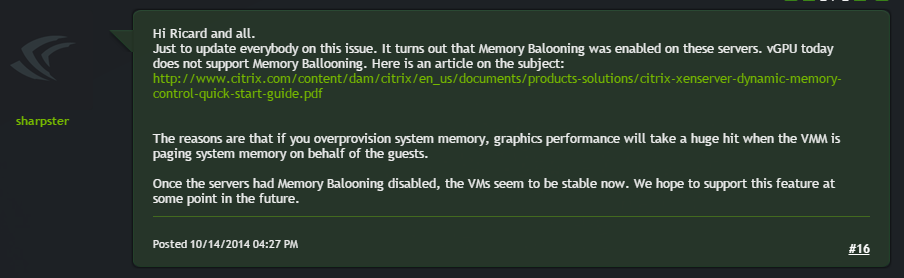
Hi Ricard and all.
Just to update everybody on this issue. It turns out that Memory Balooning was enabled on these servers. vGPU today does not support Memory Ballooning. Here is an article on the subject:http://www.citrix.com/content/dam/citrix/en_us/documents/products-solutions/citrix-xenserver-dynamic-memory-control-quick-start-guide.pdf
The reasons are that if you overprovision system memory, graphics performance will take a huge hit when the VMM is paging system memory on behalf of the guests.
Once the servers had Memory Balooning disabled, the VMs seem to be stable now. We hope to support this feature at some point in the future.
For the full forum thread, see: https://gridforums.nvidia.com/default/topic/315/nvidia-grid-drivers/xendesktop-grid-environment-blue-screening-on-directx-driver/2/
In looking into 2015 and the forthcoming release of vGPU for vSphere, I would expect these limitations to be cross-platform. In vSphere it’s a little different as the hypervisor handles this automatically using the four memory optimization techniques:
- Transparent page sharing (TPS)—reclaims memory by removing redundant pages with identical content
- Ballooning—reclaims memory by artificially increasing the memory pressure inside the guest
- Hypervisor swapping—reclaims memory by having ESX directly swap out the virtual machine’s memory
- Memory compression—reclaims memory by compressing the pages that need to be swapped out
The way you disable memory optimization in vSphere is by enforcing a reservation, however the concept is the same. Thick vs. Thin is an easy way of thinking about it.
Implications
Now, the real question comes into play here. If Dynamic Memory (or other techniques) are not available and you have to put static Memory reservations on your VDI or RDSH VMs to use NVIDIA GRID vGPU, how does that impact your single server density scalability? Is this going to throw a monkey wrench into your plans to get X number of users on Y piece of hardware? Do you always plan for 100% memory reservations for each VM, or do you allow the hypervisor to do a fair job of resource allocation? While I agree, having 100% reservations is a good practice to ensure a consistent user experience, monster VDI VMs are becoming more and more common. A couple years back, two-by-fours (2vCPU, 4GB RAM) were fairly common. Now, I am seeing more and more higher end knowledge worker use cases with 4×16, 4×32, even a couple recently that were 8×32. If thickly allocating 16GB or 32GB per user, you can see how even the beefiest of 512GB, 768GB, or 1TB box will get eaten up pretty quick. And, more often then not, these are Persistent VDI VMs due to the nature of the work these folks are doing. So it’s not like you can use Pooled/Non-Persistent VDI as a way to over-allocate access to the user population.
I know there’s a bit to think about here, but I want to start the dialog and gain awareness as the world continues to evolve. Hopefully this article was informative about the use of Dynamic Memory with NVIDIA GRID vGPU. More so, this post should get you thinking about design and sizing implications as you look to plan out your deployment using the best of the best technologies.
As always, if you have any questions, comments, or simply want to leave feedback, please do so in the comments section below. Please help me spread the news in this article so it can become common knowledge. If NVIDIA changes their stance relative to Dynamic Memory, I will be sure to update this article.
Big thanks to Richard Hoffman, Steve Harpster, Jason Southern, and Luke Wignall for sticking with this one to find a resolution.
Cheers,
@youngtech
, and XenApp/XenDesktop 5, 6, 6.5, and 7.x!")


Seems like in some cases GPU passthrough is the way to go to bypass cases where dynamic memory allocation may be a necessity. This situation may perhaps be caused because of buffering and various other memory needs such that the minimum memory setting cannot go below some threshold level. That is certainly something that could be determined empirically.
There was an interesting question posted over on the UK Citrix User Group which asked “It would seem in an environment where usage was so dynamic as to require that much allocation of resources that perhaps a better option would be to look how services might be incorporated into one or more shared XenApp instances and rather concentrate the memory allocation to XenApp, which can in some cases at least, be more efficient” – was this application dependent on a desktop OS?
Andrew,
No, the use case is much more traditional than that. Among other use cases, users need persistent VDI w/GPU for app dev and QA work being conducted and performed within hosted datacenter environment. Non-persistent and server based doesn’t work as the OS needs to match what they use today for dev and QA (Windows Client OSes). Users need admin rights due to the work that they’re performing (think Lab Manager w/vGPU).
Persistent VDI = Required. Lots of users, but simultaneous access is low. Session timeouts are OK, so the user desktops reset between use. When the desktops reset and non actively used, persistent VDI desktops have very low resource requirements to stay powered on. If you do static memory allocations, many unnecessary resources (16-32GB RAM per VM) are chewed up simply to have the desktop in a powered-on and ready state for when the user needs to connect.
While 100% usage environments probably wouldn’t be a logical fit for dynamic memory, when the access is infrequent and the concurrent is less than 50% of provisioned VMs, chewing resources just because is rather costly. Hopefully this makes a bit more sense, now with XenServer 6.5 we should be in the clear.
Thanks!
@youngtech
Curios, where are you seeing the errors listed above? In the XenCenter client or are you trying to start the VM at the command line? We are having a similar issue with BSOD using K120Q profile on XD 7.5 and XD 7.6. What is odd is everything has been working great until we added the 9 and 10th VM. I don’t have the error you got but is is bluescreening on dxgmms1.sys and we were not using DMC on the VM’s.
My workaround has to be give them the K100 profile for now. I planned on upgrading the drivers this weekend and checking the bios version of our R720.
Definitely open a new discussion in the NVIDIA GRID forums. The NVIDIA team (and Citrix) is monitoring the forums actively and are incredibly responsive there.
Thanks!
@youngtech